Your AI, your rules.
TalePal is model-tuned, not model-agnostic.
Run gemma-4-e4b locally on your laptop — or bring your API key for Gemini 2.5, GPT-4.1, or Mistral. Each model ships with its own prompts and a context budget dialed in for it.
Prompts and context, tuned per model.
We default to each provider's smaller tier — well-engineered prompts and smart context let a smaller model punch above its weight. We tested extensively to balance quality, response time, and cost. Local is pushed hardest: the whole thing runs on a MacBook Air.
Ollama / LM Studio
Run models on your own machine with Ollama or LM Studio. Private and offline.
- Recommended
gemma-4-e4b
- Completely free, no API key needed
- Context packed to ~5,000 tokens — vs 30,000+ naive
- Speed depends on your hardware
- Runs locally, complete privacy
- No costs, no internet required
Mistral
Choose Mistral for the best free tier experience.
- Small
mistral-small-2506- Default
mistral-large-2512- Big
mistral-large-2512
- Generous free tier, no credit card needed
- Good quality responses
- Fast response times
- Cloud-based
- Paid API for more context and requests
Google Gemini
Cloud-powered intelligence. Fast and excellent quality.
- Small
gemini-2.5-flash-lite- Default
gemini-2.5-flash- Big
gemini-2.5-flash
- Small free tier (20 requests/day)
- Excellent quality responses
- Fast response times
- Cloud-based
- Paid API for more context and requests
OpenAI
Industry-leading models. Powerful and versatile.
- Small
gpt-4.1-nano- Default
gpt-4.1-mini- Big
gpt-4.1
- No free tier
- Excellent quality responses
- Fast response times
- Cloud-based
- Paid API with high context window
Context is engineered — not dumped.
TalePal doesn't shove your whole manuscript at the model. Chapter summaries stand in for full chapters when the budget is tight, character profiles are tiered from short to deep, worldbuilding falls back to a summary when raw entries would overflow. On local AI it's tuned tighter still — a leaner budget, summaries over raw text — so gemma-4-e4b on your laptop answers in seconds, not minutes.
- Chapter summaries replace full chapters when token budget is tight
- Character profiles tiered short → deep, loaded on demand
- Worldbuilding switches to summary when entries overflow
- Local tuning: ~5,000 tokens packed vs 30,000+ in naive pipelines
Cloud quality, without the monthly bill.
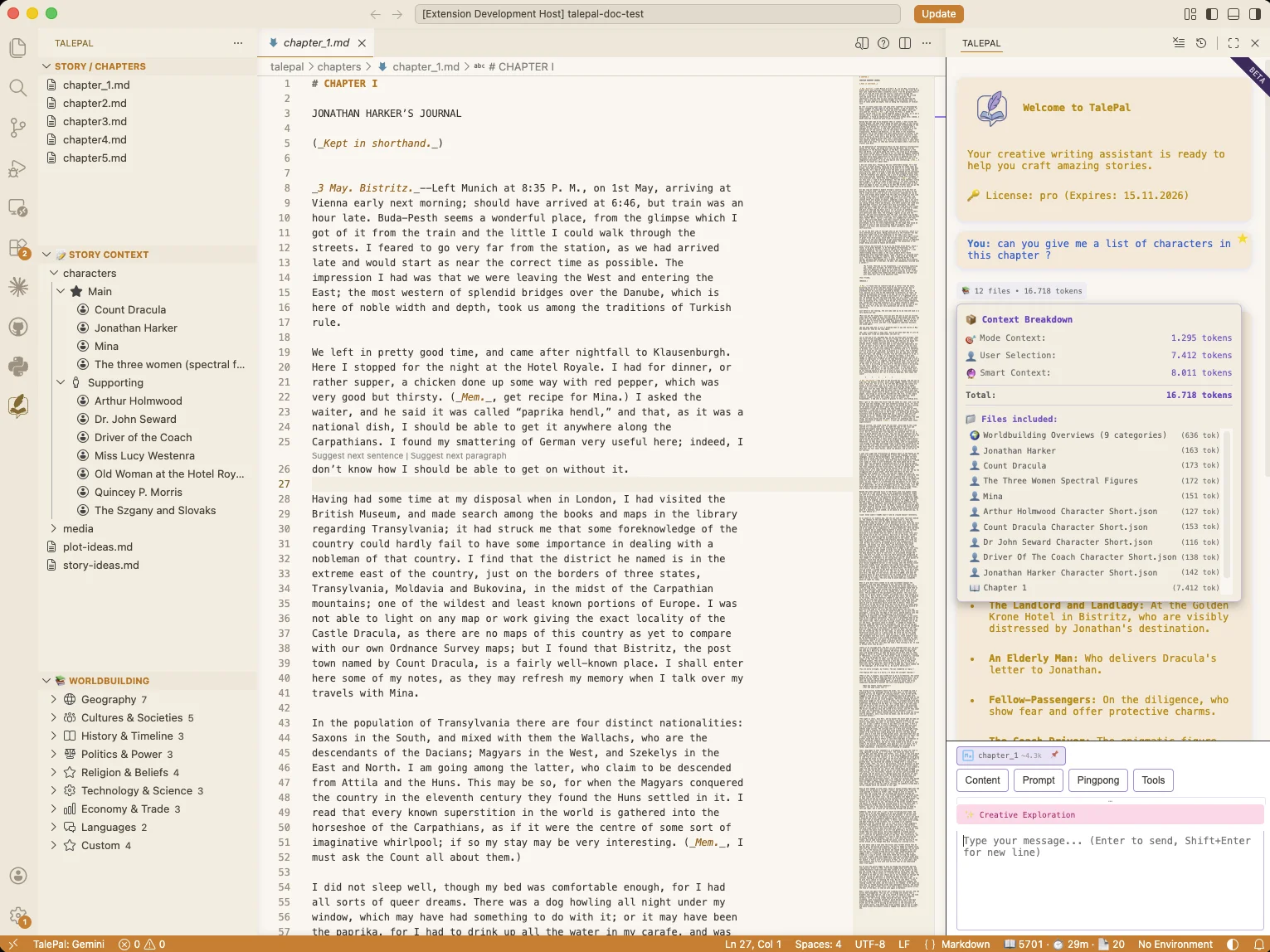
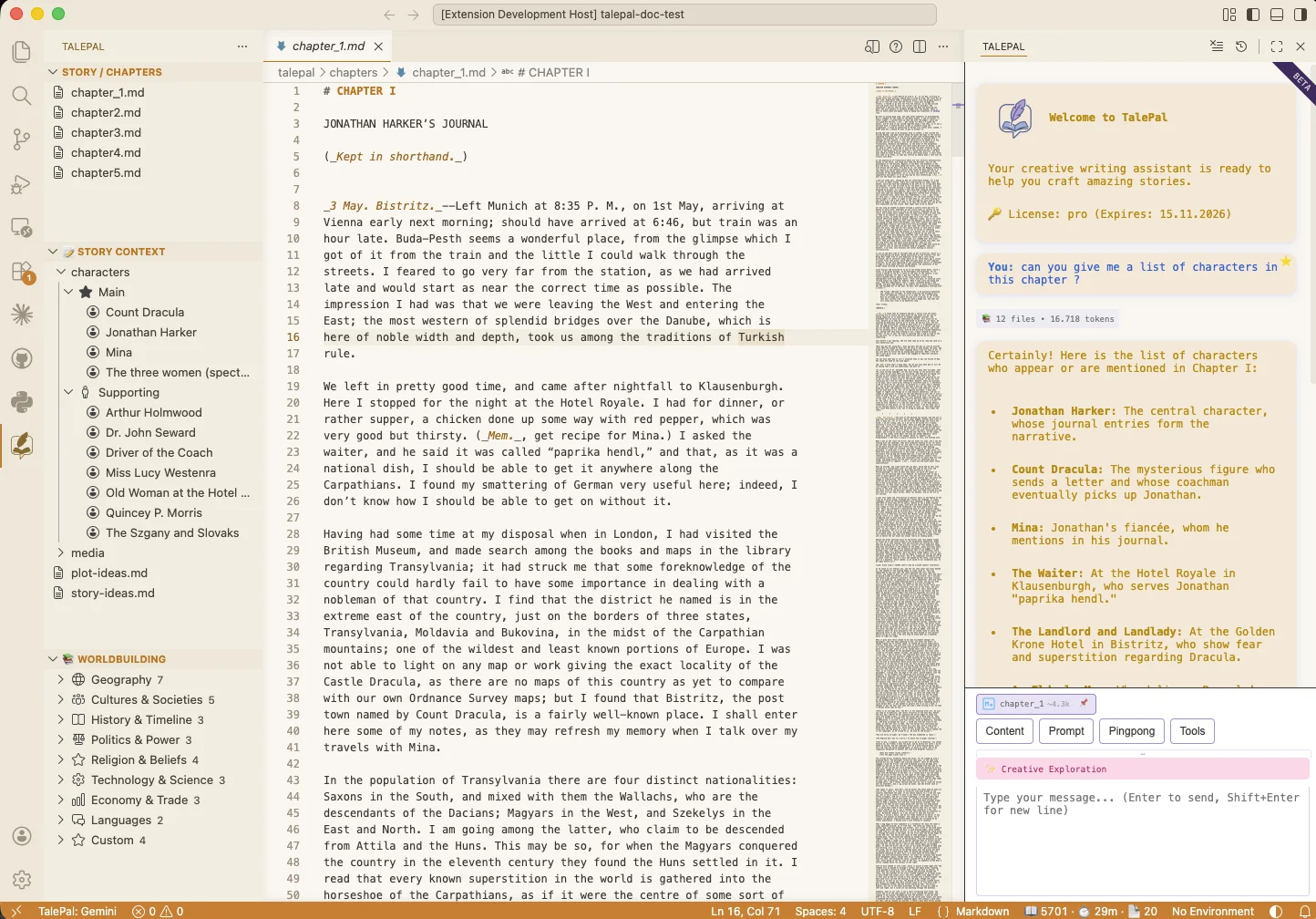
Five modes. Full experience, offline.
Point TalePal at Ollama or LM Studio, pick a model like gemma-4-e4b, and you get the whole thing offline — five dialogue modes, each one auto-loading the right context: current chapter, relevant character profiles, timeline, wiki. Cloud still works when you want raw speed. Local works when you want zero cost, zero telemetry, zero lock-in.
- Five modes: Story, Character, Plot, Worldbuilding, Creative Exploration
- Each mode auto-loads: chapter, profiles, timeline, wiki
- Typical story-mode question: ~3 s cloud · ~14 s local
- Runs 100% offline once the model is downloaded
Tested on a MacBook Air.
Pipeline timings for a 4-chapter, ~23,000-word corpus analyzed locally with gemma-4-e4b via LM Studio. MacBook Air M3.
| Pipeline step | Per-call work | In tokens | Of which chapter text | Out tokens | Median time | Typical range |
|---|---|---|---|---|---|---|
| Chapter Summary (Step 2) | One full chapter → analysis JSON | 11,700 | ~7,500 (≈5,700 words) | 2,030 | 2 m 28 s | 53 s – 3 m 11 s |
| Character Summary (Step 3) | Per-chapter character pass | 720 | (chapter summary only) | 220 | 14 s | 6 s – 33 s |
| Character Consolidation (Step 3) | Merge / dedupe cast across chapters | 4,730 | — | 10 | 15 s | 7 s – 20 s |
| Character Enhancement R1 (Step 4) | Batch short profile | 3,400 | — | 700 | 56 s | 13 s – 1 m 21 s |
| Character Enhancement R2 (Step 4) | Deep per-character analysis | 1,560 | — | 2,290 | 2 m 16 s | 29 s – 4 m 06 s |
Beyond raw timings, we benchmark models on output quality, speed, and hallucination — local and cloud, run after run.
See the full LLM benchmarks
AI should enhance your creativity, not replace it.
We don't ghostwrite. We don't lock your data. Your voice. Your story. Your way.